In this blog, I am going to discuss about the Statistical Machine Translation and the challenges in SMT to system.
Statistical machine translation
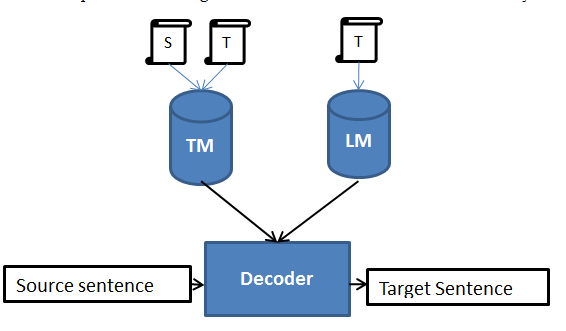
Statistical Machine Translation (SMT) is one of the corpus-based machine translation approaches. It is based on the statistical models that are built by analyzing the parallel corpus and monolingual corpus. The original idea of SMT was initiated by Brown et al. based on the Bayes Theorem. Basically, two probabilistic models are being used; Translation Model(TM) and Language Model (LM). The output is generated by maximizing the conditional probability for the target given the source language. SMT is simply described in the Figure 1. According to the translation given by human in parallel corpora, system learn the patterns and assigns probability for each translations. So according to the probability the best translation will be selected for the new translation.

Translation Model (TM)
Translation system is capable of constructing the words that retrieve its original meaning and ordering those words in a sequence that form fluent sentences in the target language. The role of the translation model is to find P(t|e) the probability of the target sentence t given the input sentence e. The training corpus for the translation model is a sentence-aligned parallel corpus of the languages f and e.
It is obvious to compute P(t|e) from counts of the sentences t and e in the parallel corpus. Again, the problem is data sparsity. The solution that is immediately apparent is to find (or approximate) the sentence translation probability using the translation probabilities of the words in the sentences. The word translation probabilities, in turn, can be found from the parallel corpus. There is another issue is that the parallel corpus gives us only the sentence alignments; it does not tell us how the words in the sentences are aligned.
A word alignment between sentences tells us exactly how each word in sentence t is translated in e. The problem is getting the word alignment probabilities given a training corpus that is only sentence aligned. This problem is solved by using the Expectation-Maximization (EM) algorithm.
Current statistical machine translation is based on the perception that a better way to compute these probabilities is by considering the behavior of phrases. The perception of phrase-based statistical machine translation is to use phrases i.e., sequences of words as well as single words as the fundamental units of translation. In phrase-based translation model, the aim is to reduce the restrictions of word-based translation by translating whole sequences of words, where the lengths may differ. The sequences of words are called blocks or phrases, but typically are not linguistic phrases but phrases found using statistical methods from corpora.
Phrase-based models work in a successful manner only if the source and the target language have almost same in word order. The difference in the order of words in phrase-based models is handled by calculating distortion probabilities. Reordering is done by the phrase-based models.
Building Translation model
E.g.
මගේ නම ගීතා වේ. எனது பெயர் கீதா.
මගේ පොත. என்னுடைய புத்தகம்
The snippet of phrase table for the given parallel sentences is given below table.
Sinhala
|
Tamil
|
P(T|E)
|
මගේ
|
எனது
|
0.66
|
මගේ
|
என்னுடைய
|
0.22
|
මගේ පොත
|
எனது புத்தகம்
|
0.72
|
මගේ නම ගීතා
|
எனது பெயர் கீதா
|
0.22
|
In general, the language model is used to ensure the fluency of the translated sentence. This plays a main role in the statistical approach as it picks the best fluent sentence with a high value of P(t) among all possible translations. The language model can be defined as the model which estimates and assigns a probability P(t) to the sentence, t. A high value will be assigned for the most fluent sentence and a low value for the least fluent sentence. The language model can be estimated from a monolingual corpus of the target language in the translation process. It gets the probability of each word according to the n-grams. Standardly it is calculated with a trigram language model.
Example, consider the following Tamil sentences,
ராம் பந்தை அடித்தான்
ராம் பந்தை வீசினான்
Even the second translation looks awkward to read, the probability assigned to the translation model to each sentence may be same, as translation model mainly concerns with producing the best output words for each word in the source sentence. But when the fluency and accuracy of the translation come into the picture, only the first translation of the given sentence is correct. This problem can be very well handled by the language models. This is because the probability assigned by the language model for the first sentence will be greater when compared with the other sentences. Table 3.2 shows the snippet of the language model.
w3
|
w1w2
|
Score
|
அடித்தான்
|
ராம் பந்தை
|
-1.855783
|
வீசினான்
|
ராம் பந்தை
|
-0.4191293
|
The Statistical Machine Translation Decoder
The statistical machine translation decoder performs decoding which is the process of discovering a target translated sentence for a source sentence using translation model and language model. In general, decoding is a search problem that maximizes the translation and language model probability. Statistical machine translation decoders use best-first search based on heuristics. In other words, the decoder is responsible for the search of best translation in the space of possible translations. Given a translation model and a language model, the decoder constructs the possible translations and look for the most probable one. Beam search decoders use a heuristic search algorithm that explores a graph by expanding the most promising node in a limited set.

In the above figure decoding process of statistical machine translation is explained using Sinhala to Tamil translation. A Sinhala input sentence “මගේ ගම යාපනය වේ” is given to decoder. Decoder looks the probability of translation for words/phrases in the phrase table which is already built in the training process. According to the probabilities, it will create tree for all possible translations. In each step probability is multiplied. The highest probability path will be selected as best translation. In this case 0.62 is best path’s probability and it will be selected as best translation.
Compare to other methods, Statistical Machine Translation suits for low resource languages. The advantages of statistical approach over other machine translation approaches are as follows:
- The enhanced usage of resources available for machine translation such as manually translated parallel and aligned texts of a language pair, books available in both languages and so on. That is, a large amount of machine-readable natural language texts is available with which this approach can be applied.
- In general, statistical machine translation systems are language independent. i.e. it is not designed specifically for a pair of language.
- Rule-based machine translation systems are generally expensive as they employ manual creation of linguistic rules and these systems cannot be generalized for other languages, whereas statistical systems can be generalized for any pair of languages if bilingual corpora for that particular language pair is available.
- Translations produced by statistical systems are more natural compared to that of other systems, as it is trained from the real-time texts available from bilingual corpora and also the fluency of the sentence will be guided by a monolingual corpus of the target language
As we saw above, SMT system is so much better than other machine translation system, there are some challenges we need to overcome for the better translation.
Common challenges of SMT system
- Out of Vocabulary: Some words in the source sentences are left as "not translated words" by the MT system since it is unknown to the translation model. The OOV can be categorized as named entities and inflection forms of verbs and nouns.
- Reordering: Different languages have different word ordering (some languages have subject-object-verb while other have subject-verb-object). When translating, extra effort is needed to make sure that the output flow is fluent.
- Word flow: Even though some languages accept free ordering when formulating sentences, according to the order of words, the meaning of sentences may differ. So, we have to be careful when translating from one language to another.
- Unknown target word/words combination to the language model: When the word or sequence of words is unknown to the language model, the system suffers from constructing fluent output as it does not have sufficient statistic on selecting among the word choices.
- The mismatch between the domain of the training data and the domain of interest: Writing style and the word usage has a radical difference from domain to domain. For example, the writing of official letters differs much from that of story writing. And the meaning of words may vary depending on the context or domain. For example, the word "cell" is translated to a "small part of the body" if the considered domain is medical while to "telephone" if the domain is computing
- A multiword expression such as collocations and idioms: Translation of such multi-word expression is beyond the level of words. Therefore, in most cases, they are incorrectly translated.
- Mismatches in the degree of inflection in of source and target languages: Each language has its own level of inflection and different morphological rules. Therefore, most of the time there will not be a one-to-one mapping between these inflections. This creates ambiguity while mapping inflection forms
- Low resourced languages: Lacks of parallel data
- Orthographical error - As the languages consist of more alphabets than the keyboard system, typing in those languages is a bit complex. In practical use, most of the time non-Unicode fonts are used in document processing, some time with local customization over the font. Though from the point of human reading usage, this makes no harm; this non-standardization in document processing makes it hard to produce linguistics resources for computer processing. In most cases, this conversion process creates orthographical errors in the data.
Its really well written and interesting piece, thank you. I was looking on machine-learning. Now I will have to make time to go through this and apply it where I can. It will really help me to complete my assignment on machine-learning training.
ReplyDeleteThank you for sharing which is pretty useful and visit ServiceNow Managed services which improves your IT and enterprise service management with a powerful range of capabilities.
ReplyDeleteNice Blog We are providing technical support in Quickbooks Support Phone Number +1-800-986-4607. if you are Expand your business to a new hike, with progressive approach. Seeking for the best accounting software? Then, get QuickBooks installed in your system.
ReplyDeleteNice Blog ! If you want more info about QuickBooks, you can call our QuickBooks Payroll Support Phone Number 855-907-0406. We will provide you with all the data you need and can also help you solve your problems you are experiencing with this accounting software.
ReplyDeleteYou also view on Map https://tinyurl.com/qksgrna
QuickBooks Support Phone Number
ReplyDeleteQuickbooks Proadvisor Support Phone Number
QuickBooks Helpline Number
Quickbooks Proadvisor Support Phone Number
Quickbooks Proadvisor Support Phone Number
QuickBooks Error 15215
QuickBooks Toll Free Phone Number
QuickBooks Support Phone Number
QuickBooks Customer Service Number
QuickBooks Pro Support Phone Number
https://yashothara.blogspot.com/2018/12/statistical-machine-translation.html?m=1#comment-form
ReplyDeletePlz fill my survey about machine translation smt and nmt
ReplyDeletehttps://forms.gle/orSKYM7pptYnRxEo6