As I am from IT background, my most of posts were related to technical stuffs. But this blog post mostly covers linguistic aspects than technical stuffs. While I am working on machine translation system between Sinhala and Tamil languages, I came up with an interesting term 'Language Divergence'. So I have written this blog to discuss about the study of the language divergence. I am going to explain the divergence study with the examples of Sinhala and Tamil languages as I am familiar with it. But why is this study important? Most of the people get this question in your mind now. When we built statistical machine translation system, it did not give perfect results for every sentence. So we have analysed the output and identified most of the errors occurred due to different nature of these languages. This is called as "Language Divergence". Formally, language divergence is is a common phenomenon in translation between two languages which occurs when sentences of the source language don’t translate into structurally similar sentences in the target language. Study of divergence is critical as differences in linguistic and extra-linguistic features in languages play pivotal roles in translation. This blog briefly explains the research we have done on the divergence study between the Sinhala and Tamil languages and an algorithm to classify the divergences in the parallel corpora.
The study by our team built on the Machine Translation Divergences concept introduced by Bonnie J. Dorr. In 1994, Dorr demonstrated a systematic solution to the divergence issues. Dorr classifies translation divergences into two broad types as syntactic divergence and lexical-semantic divergence. And, these main categorizations are further subcategorized into 7 subcategories. As many of the researches have focused on Lexical-Semantic divergence among two categories given in Dorr’s classification and Sinhala and Tamil languages are mostly show the structural convergence patterns, we too consider the subcategories of Lexical-semantic divergence.
Accordingly, this research has the twin aims of revisiting classification of divergence types as outlined by Dorr and outlining some of the new divergence patterns specific to Sinhala and Tamil languages. Since these two languages are considered as low resource, morphologically rich and highly inflected languages, these efforts gain more importance.
In this research, we propose a rule-based algorithm to classify a divergence. The results of the traditional SMT system are used here to identify the translation divergence. According to the Dorr’s classification, we have come up with rules to handle those divergences. The results of the language divergence were discussed with three linguistically capable people in both Tamil and Sinhala languages. Given an input Sinhala sentence and corresponding Tamil sentence, the proposed technique aims at recognizing the occurrence of divergence in the translation.
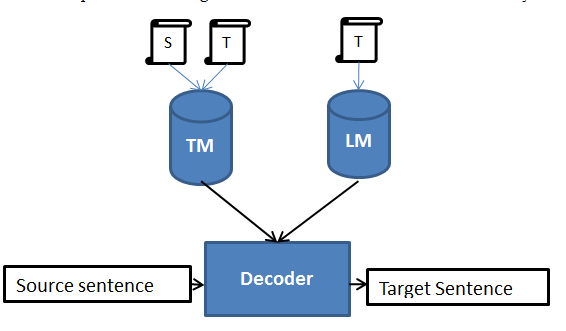
The methodology used to identify the divergence is shown in the Figure I.

In concluding, this research focused only on the lexical semantic divergence of Sinhala and Tamil languages. However, syntactic divergence among Sinhala and Tamil languages should also be analyzed.
The slideset from the IALP presentation is here.
The study by our team built on the Machine Translation Divergences concept introduced by Bonnie J. Dorr. In 1994, Dorr demonstrated a systematic solution to the divergence issues. Dorr classifies translation divergences into two broad types as syntactic divergence and lexical-semantic divergence. And, these main categorizations are further subcategorized into 7 subcategories. As many of the researches have focused on Lexical-Semantic divergence among two categories given in Dorr’s classification and Sinhala and Tamil languages are mostly show the structural convergence patterns, we too consider the subcategories of Lexical-semantic divergence.
Accordingly, this research has the twin aims of revisiting classification of divergence types as outlined by Dorr and outlining some of the new divergence patterns specific to Sinhala and Tamil languages. Since these two languages are considered as low resource, morphologically rich and highly inflected languages, these efforts gain more importance.
In this research, we propose a rule-based algorithm to classify a divergence. The results of the traditional SMT system are used here to identify the translation divergence. According to the Dorr’s classification, we have come up with rules to handle those divergences. The results of the language divergence were discussed with three linguistically capable people in both Tamil and Sinhala languages. Given an input Sinhala sentence and corresponding Tamil sentence, the proposed technique aims at recognizing the occurrence of divergence in the translation.
The methodology used to identify the divergence is shown in the Figure I.

Taking Dorr's classification, 5 types out of 7 are
identified for Sinhala-to-Tamil translation. Some additional
divergence types which do not fall under the Dorr’s classification
are also identified for Sinhala-to-Tamil translations.
This research was presented in November at the International Conference on Asian Language Processing (IALP) in Bandung, Indoneasia. The authors discussed further exploratory analysis conducted using proposed technique. The examples for the each divergence are mentioned in the paper.
This research was presented in November at the International Conference on Asian Language Processing (IALP) in Bandung, Indoneasia. The authors discussed further exploratory analysis conducted using proposed technique. The examples for the each divergence are mentioned in the paper.
In concluding, this research focused only on the lexical semantic divergence of Sinhala and Tamil languages. However, syntactic divergence among Sinhala and Tamil languages should also be analyzed.
The slideset from the IALP presentation is here.